This is the first tutorial in a new series of GPU path tracing tutorials which will focus on OpenCL based rendering. The first few tutorials will cover the very basics of getting started with OpenCL and OpenCL based ray tracing and path tracing of simple scenes. Follow-up tutorials will use a cut-down version of AMD's RadeonRays framework (the framework formerly known as FireRays), to start from as a basis to add new features in a modular manner. The goal is to incrementally work up to include all the features of RadeonRays, a full-featured GPU path tracer. The Radeon Rays source also forms the basis of AMD's Radeon ProRender Technology (which will also be integrated as a native GPU renderer in an upcoming version of Maxon's Cinema4D). In the end, developers that are new to rendering should be able to code up their own GPU renderer and integrate it into their application.
Why OpenCL?
The major benefit of OpenCL is its platform independence, meaning that the same code can run on CPUs and GPUs made by AMD, Nvidia and Intel (in theory at least, in practice there are quite a few implementation differences between the various platforms). The tutorials in this series should thus run on any PC, regardless of GPU vendor (moreover a GPU is not even required to run the program).
Another advantage of OpenCL is that it can use all the available CPU and GPUs in a system simultaneously to accelerate parallel workloads (such as rendering or physics simulations).
In order to achieve this flexibility, some boiler plate code is required which selects an OpenCL platform (e.g. AMD or Nvidia) and one or more OpenCL devices (CPUs or GPUs). In addition, the OpenCL source must be compiled at runtime (unless the platform and device are known in advance), which adds some initialisation time when the program is first run.
OpenCL execution model quick overview
This is a superquick overview OpenCL execution model, just enough to get started (there are plenty of more exhaustive sources on OpenCL available on the web).
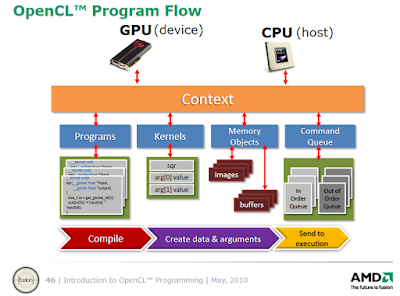
In order to run an OpenCL program, the following structures are required (and are provided by the OpenCL API):
- Platform: which vendor (AMD/Nvidia/Intel)
- Device: CPU, GPU, APU or integrated GPU
- Context: the runtime interface between the host (CPU) and device (GPU or CPU) which manages all the OpenCL resources (programs, kernels, command queue, buffers). It receives and distributes kernels and transfers data.
- Program: the entire OpenCL program (one or more kernels and device functions)
- Kernel: the starting point into the OpenCL program, analogous to the main() function in a CPU program. Kernels are called from the host (CPU). They represent the basic units of executable code that run on an OpenCL device and are preceded by the keyword "__kernel"
- Command queue: the command queue allows kernel execution commands to be sent to the device (execution can be in-order or out-of-order)
- Memory objects: buffers and images
These structures are summarised in the diagram below (slide from AMD's Introduction to OpenCL programming):
 |
| OpenCL execution model |
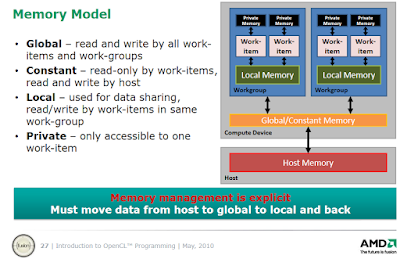
OpenCL memory model quick overview
The full details of the memory model are beyond the scope of this first tutorial, but we'll cover the basics here to get some understanding on how a kernel is executed on the device.
There are four levels of memory on an OpenCL device, forming a memory hierarchy (from large and slow to tiny and fast memory):
- Global memory (similar to RAM): the largest but also slowest form of memory, can be read and written to by all work items (threads) and all work groups on the device and can also be read/written by the host (CPU).
- Constant memory: a small chunk of global memory on the device, can be read by all work items on the device (but not written to) and can be read/written by the host. Constant memory is slightly faster than global memory.
- Local memory (similar to cache memory on the CPU): memory shared among work items in the same work group (work items executing together on the same compute unit are grouped into work groups). Local memory allows work items belonging to the same work group to share results. Local memory is much faster than global memory (up to 100x).
- Private memory (similar to registers on the CPU): the fastest type of memory. Each work item (thread) has a tiny amount of private memory to store intermediate results that can only be used by that work item
First OpenCL program
With the obligatory theory out of the way, it's time to dive into the code. To get used to the OpenCL syntax, this first program will be very simple (nothing earth shattering yet): the code will just add the corresponding elements of two floating number arrays together in parallel (all at once).
In a nutshell, what happens is the following:
In a nutshell, what happens is the following:
- Initialise the OpenCL computing environment: create a platform, device, context, command queue, program and kernel and set up the kernel arguments
- Create two floating point number arrays on the host side and copy them to the OpenCL device
- Make OpenCL perform the computation in parallel (by determining global and local worksizes and launching the kernel)
- Copy the results of the computation from the device to the host
- Print the results to the console
The code contains plenty of comments to clarify the new syntax:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
// by Sam Lapere, 2016, http://raytracey.blogspot.com
// Code based on http://simpleopencl.blogspot.com/2013/06/tutorial-simple-start-with-opencl-and-c.html
#include <iostream>
#include <vector>
#include <CL\cl.hpp> // main OpenCL include file
usingnamespace cl;
usingnamespace std;
void main()
{
// Find all available OpenCL platforms (e.g. AMD, Nvidia, Intel)
vector<Platform> platforms;
Platform::get(&platforms);
// Show the names of all available OpenCL platforms
cout << "Available OpenCL platforms: \n\n";
for (unsignedint i = 0; i < platforms.size(); i++)
cout << "\t"<< i + 1 << ": "<< platforms[i].getInfo<CL_PLATFORM_NAME>() << endl;
// Choose and create an OpenCL platform
cout << endl << "Enter the number of the OpenCL platform you want to use: ";
unsignedint input = 0;
cin >> input;
// Handle incorrect user input
while (input < 1 || input > platforms.size()){
cin.clear(); //clear errors/bad flags on cin
cin.ignore(cin.rdbuf()->in_avail(), '\n'); // ignores exact number of chars in cin buffer
cout << "No such platform."<< endl << "Enter the number of the OpenCL platform you want to use: ";
cin >> input;
}
Platform platform = platforms[input - 1];
// Print the name of chosen OpenCL platform
cout << "Using OpenCL platform: \t"<< platform.getInfo<CL_PLATFORM_NAME>() << endl;
// Find all available OpenCL devices (e.g. CPU, GPU or integrated GPU)
vector<Device> devices;
platform.getDevices(CL_DEVICE_TYPE_ALL, &devices);
// Print the names of all available OpenCL devices on the chosen platform
cout << "Available OpenCL devices on this platform: "<< endl << endl;
for (unsignedint i = 0; i < devices.size(); i++)
cout << "\t"<< i + 1 << ": "<< devices[i].getInfo<CL_DEVICE_NAME>() << endl;
// Choose an OpenCL device
cout << endl << "Enter the number of the OpenCL device you want to use: ";
input = 0;
cin >> input;
// Handle incorrect user input
while (input < 1 || input > devices.size()){
cin.clear(); //clear errors/bad flags on cin
cin.ignore(cin.rdbuf()->in_avail(), '\n'); // ignores exact number of chars in cin buffer
cout << "No such device. Enter the number of the OpenCL device you want to use: ";
cin >> input;
}
Device device = devices[input - 1];
// Print the name of the chosen OpenCL device
cout << endl << "Using OpenCL device: \t"<< device.getInfo<CL_DEVICE_NAME>() << endl << endl;
// Create an OpenCL context on that device.
// the context manages all the OpenCL resources
Context context = Context(device);
///////////////////
// OPENCL KERNEL //
///////////////////
// the OpenCL kernel in this tutorial is a simple program that adds two float arrays in parallel
// the source code of the OpenCL kernel is passed as a string to the host
// the "__global" keyword denotes that "global" device memory is used, which can be read and written
// to by all work items (threads) and all work groups on the device and can also be read/written by the host (CPU)
constchar* source_string =
" __kernel void parallel_add(__global float* x, __global float* y, __global float* z){ "
" const int i = get_global_id(0); "// get a unique number identifying the work item in the global pool
" z[i] = y[i] + x[i]; "// add two arrays
"}";
// Create an OpenCL program by performing runtime source compilation
Program program = Program(context, source_string);
// Build the program and check for compilation errors
cl_int result = program.build({ device }, "");
if (result) cout << "Error during compilation! ("<< result << ")"<< endl;
// Create a kernel (entry point in the OpenCL source program)
// kernels are the basic units of executable code that run on the OpenCL device
// the kernel forms the starting point into the OpenCL program, analogous to main() in CPU code
// kernels can be called from the host (CPU)
Kernel kernel = Kernel(program, "parallel_add");
// Create input data arrays on the host (= CPU)
constint numElements = 10;
float cpuArrayA[numElements] = { 0.0f, 1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f, 9.0f };
float cpuArrayB[numElements] = { 0.1f, 0.2f, 0.3f, 0.4f, 0.5f, 0.6f, 0.7f, 0.8f, 0.9f, 1.0f };
float cpuOutput[numElements] = {}; // empty array for storing the results of the OpenCL program
// Create buffers (memory objects) on the OpenCL device, allocate memory and copy input data to device.
// Flags indicate how the buffer should be used e.g. read-only, write-only, read-write
Buffer clBufferA = Buffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, numElements * sizeof(cl_int), cpuArrayA);
Buffer clBufferB = Buffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, numElements * sizeof(cl_int), cpuArrayB);
Buffer clOutput = Buffer(context, CL_MEM_WRITE_ONLY, numElements * sizeof(cl_int), NULL);
// Specify the arguments for the OpenCL kernel
// (the arguments are __global float* x, __global float* y and __global float* z)
kernel.setArg(0, clBufferA); // first argument
kernel.setArg(1, clBufferB); // second argument
kernel.setArg(2, clOutput); // third argument
// Create a command queue for the OpenCL device
// the command queue allows kernel execution commands to be sent to the device
CommandQueue queue = CommandQueue(context, device);
// Determine the global and local number of "work items"
// The global work size is the total number of work items (threads) that execute in parallel
// Work items executing together on the same compute unit are grouped into "work groups"
// The local work size defines the number of work items in each work group
// Important: global_work_size must be an integer multiple of local_work_size
std::size_t global_work_size = numElements;
std::size_t local_work_size = 10; // could also be 1, 2 or 5 in this example
// when local_work_size equals 10, all ten number pairs from both arrays will be added together in one go
// Launch the kernel and specify the global and local number of work items (threads)
queue.enqueueNDRangeKernel(kernel, NULL, global_work_size, local_work_size);
// Read and copy OpenCL output to CPU
// the "CL_TRUE" flag blocks the read operation until all work items have finished their computation
queue.enqueueReadBuffer(clOutput, CL_TRUE, 0, numElements * sizeof(cl_float), cpuOutput);
// Print results to console
for (int i = 0; i < numElements; i++)
cout << cpuArrayA[i] << " + "<< cpuArrayB[i] << " = "<< cpuOutput[i] << endl;
system("PAUSE");
}
This code is also available at
https://github.com/straaljager/OpenCL-path-tracing-tutorial-1-Getting-started
https://github.com/straaljager/OpenCL-path-tracing-tutorial-1-Getting-started
Compiling instructions(for Visual Studio on Windows)
To compile this code, it's recommended to download and install the AMD App SDK (this works for systems with GPUs or CPUs from AMD, Nvidia and Intel, even if your system doesn't have an AMD CPU or GPU installed) since Nvidia's OpenCL implementation is no longer up-to-date.
- Start an empty Console project in Visual Studio (any recent version should work, including Express and Community) and set to Release mode
- Add the SDK include path to the "Additional Include Directories" (e.g. "C:\Program Files (x86)\AMD APP SDK\2.9-1\include")
- In Linker > Input, add "opencl.lib" to "Additional Dependencies" and add the OpenCL lib path to "Additional Library Directories" (e.g. "C:\Program Files (x86)\AMD APP SDK\2.9-1\lib\x86")
- Add the main.cpp file (or create a new file and paste the code) and build the project
Download binaries
The executable (Windows only) for this tutorial is available at
https://github.com/straaljager/OpenCL-path-tracing-tutorial-1-Getting-started/releases/tag/v1.0
It runs on CPUs and/or GPUs from AMD, Nvidia and Intel.
https://github.com/straaljager/OpenCL-path-tracing-tutorial-1-Getting-started/releases/tag/v1.0
It runs on CPUs and/or GPUs from AMD, Nvidia and Intel.
Useful References
- "A gentle introduction to OpenCL":
http://www.drdobbs.com/parallel/a-gentle-introduction-to-opencl/231002854
- "Simple start with OpenCL":
http://simpleopencl.blogspot.co.nz/2013/06/tutorial-simple-start-with-opencl-and-c.html
- Anteru's blogpost, Getting started with OpenCL (uses old OpenCL API)
https://anteru.net/blog/2012/11/03/2009/index.html
- AMD introduction to OpenCL programming:
http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2013/01/Introduction_to_OpenCL_Programming-201005.pdf
Up next
In the next tutorial we'll start rendering an image with OpenCL.