For this tutorial, I've implemented a couple of improvements based on the high performance GPU ray tracing framework of Timo Aila, Samuli Laine and Tero Karras (Nvidia research) which is described in their 2009 paper "Understanding the efficiency of ray traversal on GPUs" and the 2012 addendum to the original paper which contains specifically hand tuned kernels for Fermi and Kepler GPUs (which also works on Maxwell). The code for this framework is open source and can be found at the Google code repository (which is about to be phased out) or on GitHub. The ray tracing kernels are thoroughly optimised and deliver state-of-the-art performance (the code from this tutorial is 2-3 times faster than the previous one). For that reason, they are also used in the production grade CUDA path tracer Cycles:
- wiki.blender.org/index.php/Dev:Source/Render/Cycles/BVH
- github.com/doug65536/blender/blob/master/intern/cycles/kernel/kernel_bvh.h
- github.com/doug65536/blender/blob/master/intern/cycles/kernel/kernel_bvh_traversal.h
- wiki.blender.org/index.php/Dev:Source/Render/Cycles/BVH
- github.com/doug65536/blender/blob/master/intern/cycles/kernel/kernel_bvh.h
- github.com/doug65536/blender/blob/master/intern/cycles/kernel/kernel_bvh_traversal.h
The major improvements from this framework are:
- Spatial split BVH: this BVH building method is based on Nvidia's "Spatial splits in bounding volume hierarchies" paper by Martin Stich. It aims to reduce BVH node overlap (a high amount of node overlap lowers ray tracing performance) by combining the object splitting strategy of regular BVH building (according to a surface area heuristic or SAH) with the space splitting method of kd-tree building. The algorithm determines for each triangle whether "splitting" it (by creating duplicate references to the triangle and storing them in its overlapping nodes) lowers the cost of ray/node intersections compared to the "unsplit" case. The result is a very high quality acceleration structure with ray traversal performance which on average is significantly higher than (or in the worst case equal to) a regular SAH BVH.
- Woop ray/triangle intersection: this algorithm is explained in "Real-time ray tracing of dynamic scenes on an FPGA chip". It basically transforms each triangle in the mesh to a unit triangle with vertices (0, 0, 0), (1, 0, 0) and (0, 1, 0). During rendering, a ray is transformed into "unit triangle space" using a triangle specific affine triangle transformation and intersected with the unit triangle, which is a much simpler computation.
- Hand optimised GPU ray traversal and intersection kernels: these kernels use a number of specific tricks to minimise thread divergence within a warp (a warp is a group of 32 SIMD threads which operate in lockstep, i.e. all threads within a warp must execute the same instructions). Thread divergence occurs when one or more threads within a warp follow a different code execution branch, which (in the absolute worst case) could lead to a scenario where only one thread is active while the other 31 threads in the warp are idling, waiting for it to finish. Using "persistent threads" aims to mitigate this problem: when a predefined number of CUDA threads within a warp is idling, the GPU will dynamically fetch new work for these threads in order to increase compute occupancy. The persistent threads feature is used in the original framework. To keep things simple for this tutorial, it has not been implemented as it requires generating and buffering batches of rays, but it is relatively easy to add. Another optimisation to increase SIMD efficiency in a warp is postponing ray/triangle intersection tests until all threads in the same warp have found a leaf node. Robbin Marcus wrote a very informative blogpost about these specific optimisations. In addition to these tricks, the Kepler kernel also uses the GPUs video instructions to perform min/max operations (see "renderkernel.cu" at the top).
Other new features:
- a basic OBJ loader which triangulates n-sided faces (n-gons, triangle fans)
- simple HDR environment map lighting, which for simplicity does not use any filtering (hence the blockiness) or importance sampling yet. The code is based on http://blog.hvidtfeldts.net/index.php/2012/10/image-based-lighting/
Some renders with the code from this tutorial (the "Roman Settlement" city scene was created by LordGood and converted from a SketchUp model, also used by Mitsuba Render. The HDR maps are available at the HDR Labs website):








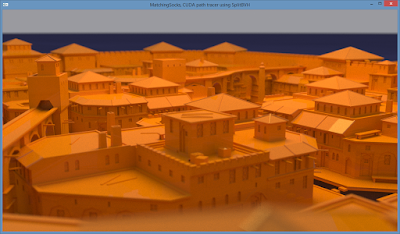
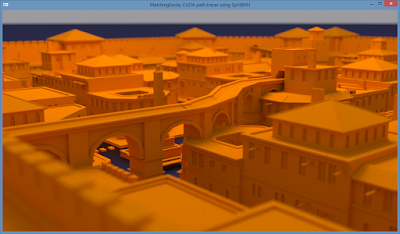
Source code
The tutorial's source code can be found at github.com/straaljager/GPU-path-tracing-tutorial-4
For clarity, I've tried to simplify the code where possible, keeping the essential improvements provided by the framework and cutting out the unnecessary parts. I have also added clarifying comments to the most difficult code parts where appropriate. There is quite a lot of new code, but the most important and interesting files are:
- SplitBVHBuilder.cpp contains the algorithm for building BVH with spatial splits
- CudaBVH.cppshows the particular layout in which the BVH nodes are stored and Woop's triangle transformation method
- renderkernel.cudemonstrates two methods of ray/triangle intersection: a regular ray/triangle intersection algorithm similar to the one in GPU path tracing tutorial 3, denoted as DEBUGintersectBVHandTriangles() and a method using Woop's ray/triangle intersection named intersectBVHandTriangles()
- SplitBVHBuilder.cpp contains the algorithm for building BVH with spatial splits
- CudaBVH.cppshows the particular layout in which the BVH nodes are stored and Woop's triangle transformation method
- renderkernel.cudemonstrates two methods of ray/triangle intersection: a regular ray/triangle intersection algorithm similar to the one in GPU path tracing tutorial 3, denoted as DEBUGintersectBVHandTriangles() and a method using Woop's ray/triangle intersection named intersectBVHandTriangles()
Demo
A downloadable demo (which requires an Nvidia GPU) is available from
github.com/straaljager/GPU-path-tracing-tutorial-4/releases
github.com/straaljager/GPU-path-tracing-tutorial-4/releases
Working with and learning this ray tracing framework was a lot of fun, head scratching and cursing (mostly the latter). It has given me a deeper appreciation for both the intricacies and strengths of GPUs and taught me a multitude of ways of how to optimise Cuda code to maximise performance (even to the level of assembly/PTX). I recommend anyone who wants to build a GPU renderer to sink their teeth in it (the source code in this tutorial should make it easier to digest the complexities). It keeps astounding me what GPUs are capable of and how much they have evolved in the last decade.
The next tutorial(s) will cover direct lighting, physical sky, area lights, textures and instancing. I've also had a few requests from people who are new to ray tracing for a more thorough explanation of the code from previous tutorials. At some point (when time permits), I hope to create tutorials with illustrations and pseudocode of all the concepts covered.